Personality LLM Research
Fine-Tuning LLM for Personality Detection
Overview:
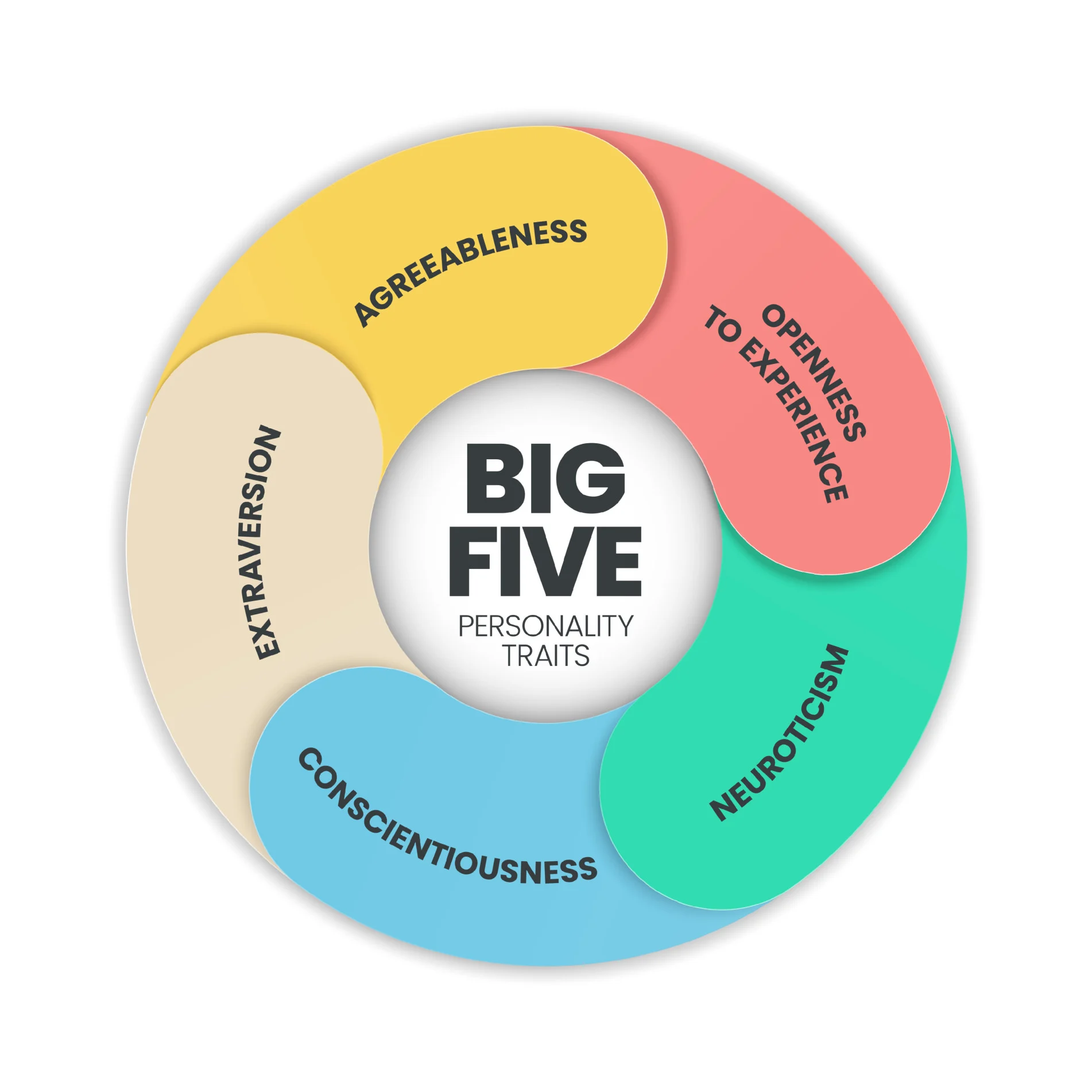
- Using PyTorch and Transformer to fine-tune a custom LLM to predict Big-Five Personality Traits
- Preprocessed real-life interview data with Pandas and NLTK to fine-tune BERT and Llama transformers
- Using Vim in command line interface to edit shell scripts that schedules batch jobs; utilizing directories and commands in Linux Command Line Interface to run batch jobs that trains model on HPC
- Proposes accurate personality prediction for interview data to the academic field of NLP and Computational Linguistics
- Extracted fine-tuned roBERTa embeddings for novel methodologies for efficient regression tasks
Paper Abstract:
Recent advancements in artificial intelligence (AI) offer promising psychological research and practice opportunities. Natural language processing (NLP) techniques have the potential to transform psychological assessments, moving beyond traditional closed-ended questionnaires to more detailed, language-based evaluations. However, large language models (LLMs) are constrained by the number of tokens they can process, limiting their ability to effectively contextualize longer texts. In this study, we use lengthy life narrative texts from older adults, each exceeding 2000 tokens. The NEO-Personality Inventory-Revised (NEO-PI-R) self-report questionnaire was administered to assess the Five-Factor Model (FFM) personality traits: extraversion, agreeableness, openness, conscientiousness, and neuroticism. We employ a hierarchical transformer approach, involving the fine-tuning of pre-trained language models with a sliding-window technique, followed by the use of recurrent neural networks (RNNs) with attention layers to capture the full context. This hybrid approach benefits from meaningful contextual text embeddings from pre-trained models into smaller windows, while the RNNs effectively manage the long context — a limitation of language models. We analyze attention weights from RNN attention layers through different interpretability techniques to validate the model’s results. When compared with state-of-the-art large language models, the hierarchical method demonstrated not only superior performance but also resource and time efficiency.
Methodology:
Throughout this research, I have gained experience in fine-tuning large language models (LLMs) for various natural language processing tasks, including predicting personality using Big-Five Personality Traits. Specifically, I have worked with advanced transformer architectures such as RoBERTa and fine-tuned them for regression tasks using the simpletransformers and transformers library. This involved preprocessing interview transcripts and handling large datasets with complex contextual relationships in the text. I have expertise in optimizing hyperparameters such as sequence length, learning rate, and batch size for high-performance training, while utilizing techniques like sliding windows to manage long text sequences.
Additionally, I have implemented 5-fold cross-validation to ensure robust model evaluation and mitigate overfitting, leveraging HPC (high-performance computing) resources for job scheduling and large-scale batch training. My work also includes fine-tuning models for both trait detection and personality disorder assessments, with a focus on capturing nuanced linguistic cues in life-narratives. Furthermore, I am skilled in debugging, configuring gradient accumulation to optimize memory usage, and using early stopping criteria to monitor performance and prevent overfitting. While I have also experimented with other cutting-edge models such as LLaMA, RoBERTa has proven to be more effective in capturing the bidirectional attention necessary for the specific tasks I have worked on.
I have also developed a strong understanding of the Big-Five Personality Traits and their linguistic correlates, which has been crucial in interpreting model predictions and identifying areas for improvement. I have also explored the use of RoBERTa embeddings for downstream tasks, such as clustering and visualization, to gain insights into the latent structure of the data. Overall, my research has provided me with a deep understanding of the challenges and opportunities in fine-tuning LLMs for personality prediction and has equipped me with the skills to tackle complex NLP tasks in the future.
For the paper submission to COLING 2025 through ACL ARR June 2024, I have contributed as the 3rd author by providing only the preprocessed text data by turning all text to lowercase, deleting outliers and formulating the data into CSV and JSON files.
Since the paper submissions to the Journal of Psychopathology and Clinical Science and to the Transactions of the Association for Computational Linguistics are still under review, I cannot fully disclose the rest of research methodologies in detail. Therefore I hope you enjoyed my description of my work, and I am excited to continue exploring the possibilities of LLMs in NLP and to contribute to cutting-edge research in this field.
I have gained permission from my research advisor, Dr. Mehak Gupta to disclose our research’s abstract and part of the methodologies